
Ensemble learning for Deep neural network
Lá bài “Polymerization” là một lá bài hết sức quen thuộc và chắc cũng tính vào dạng tuổi thơ của bao người. Và để đưa bao người về với tuổi thơ, hôm nay mình viết về một chủ đề rất thông dụng trong các cuộc thi và có thể coi là cực kỳ hiệu quả - Ensemble learning.
Ensemble learning on Machine learning:
Ensemble learning cũng coi là một chủ đề có từ lâu, nếu có thời gian thì bạn có thể xem nhiều bài viết hoặc video. Tại đây thì mình chỉ giới thiệu bằng 3 cái hình ảnh mô tả cách hoạt động của 3 method này:
Bagging:
Đây là method có thể coi là được biết đến nhiều nhất và thông dụng bậc nhất của ensemble-learning. Bagging tập trung vào việc sử dụng cùng 1 architect nhưng được train trên nhưng bộ dataset mới(được khởi tạo dựa trên bộ dataset cũ bằng cách chia random). Có thể hình dung nó như cách xây dựng Random Forest bằng kỹ thuật Bootstrapping(random sampling with replacement).
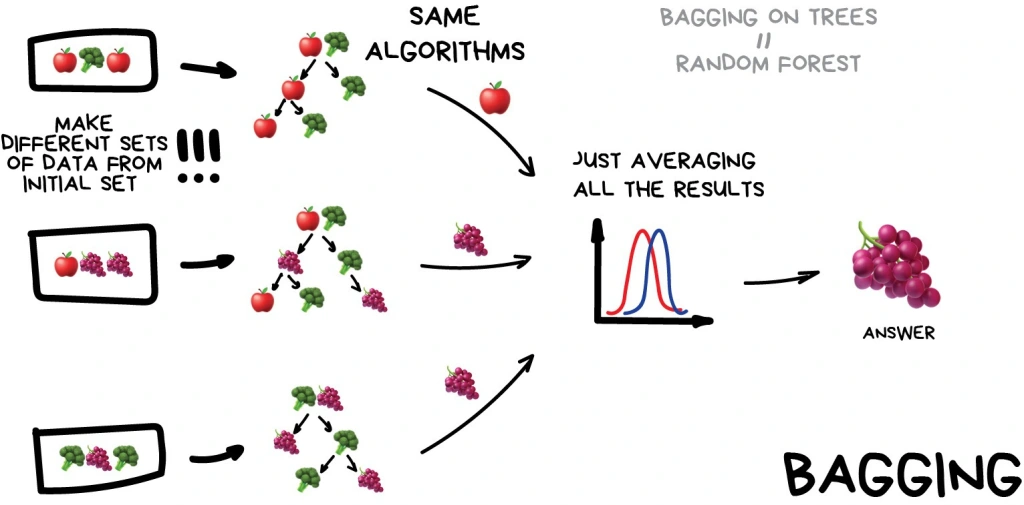
Boosting:
Boosting lại là 1 method mình thấy nó ảo ma. Khi xây dựng Boosting ta tin rằng model liền sau sẽ học từ những lỗi sai của model liền trước để từ đó chọn lựa bộ trọng số tốt nhất. Kiểu gen đời F1 có cái gì tốt là giữ lại hết còn cái gì chưa tốt thì mình lại để đời F2 update. Cứ update dần dà cho đến cuối thì mình sẽ có 1 model tụ hội được sức mạnh của các đời trước (Lâu lâu nó tổng hợp luôn overfitting thì chết cả bầy).
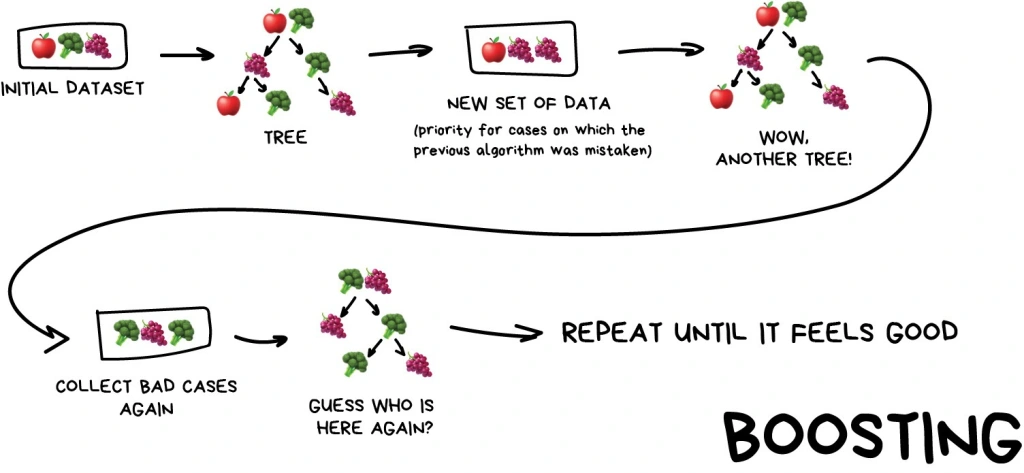
Stacking:
Stacking thì đích thị là 5 anh em siêu nhân luôn vì bản chất của method này là mình sẽ train nhiều architect khác nhau sau đó dùng 1 meta model kết hợp kết quả của các model đã train kia.
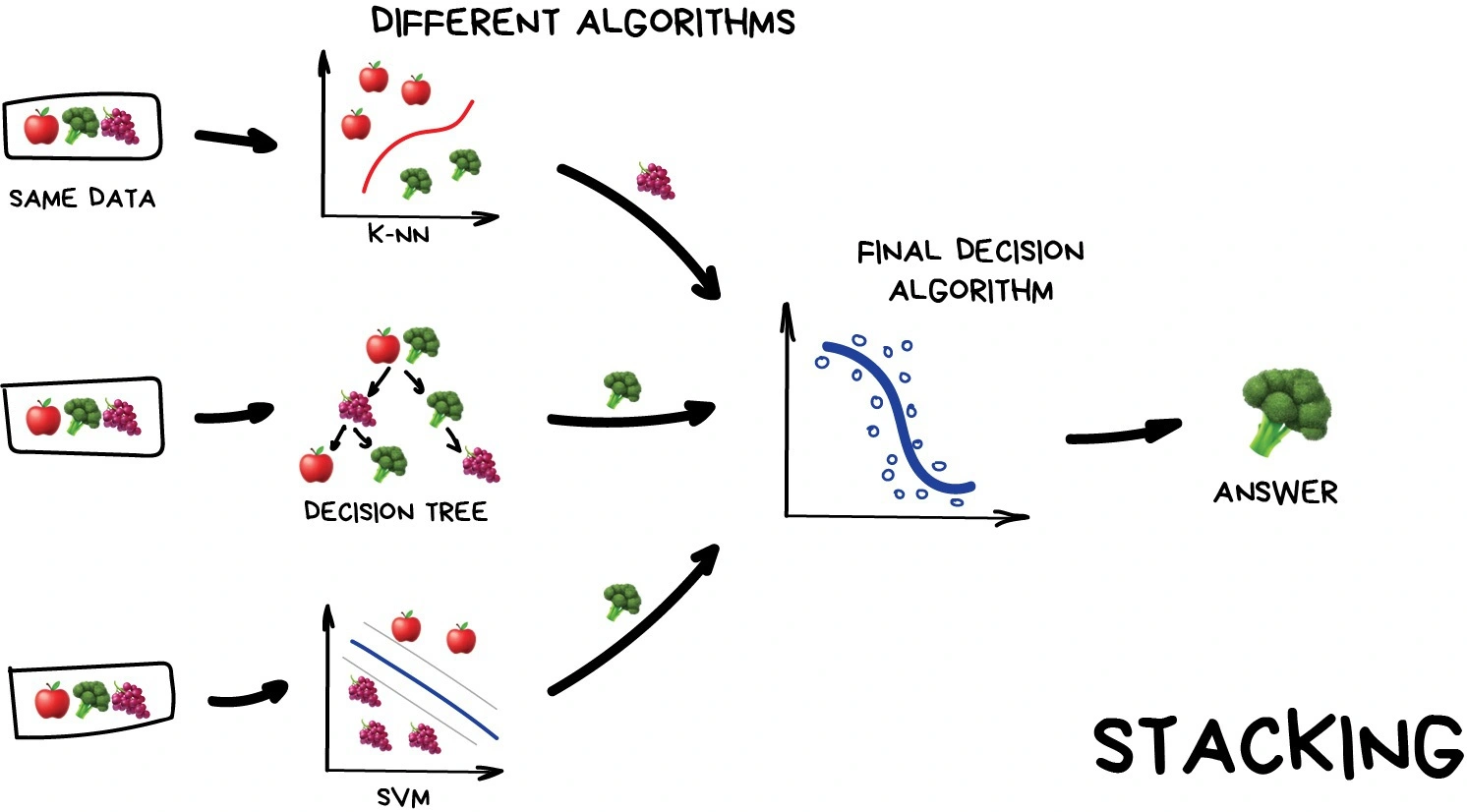
Một số nhận xét thú vị về các method trên:
Bagging:
- Phương pháp này thực hiện việc xây dựng cái model song song và tách biệt.
- Bagging được sử dụng khi model của bạn bị overfitting và hình huống này có thể giống với khi gặp tình trạng high variance - low bias.
- Mục đích của Bagging là cho model tiếp xúc với những phần khác nhau của data từ đó bạn sẽ có 1 tập các model cùng architect với variance nhỏ hơn.
Boosting:
- Khác với Bagging, Boosting thực hiện xây dựng meta model một cách tuần tự.
- Boosting được sử dụng khi model của bạn đang bị underfitting và có thể coi đây là khi model bị tình huống high bias - low variance.
- Mục đích của Boosting có thể coi như việc ta sẽ cố gắng phát triển model ở nhưng case mà model của ta đang quá đơn giản( kết quả ở những case này khá tệ). Nhờ final model đạt hiệu quả cao vì nó đang cố overfit data đang có :))).
Stacking:
- Method này khá là dị tại mình hình dung Stacking như cách chúng ta ôn thi THPTQG dị. Mình sẽ cố gắng tiếp cận nhiều cách giải nhất có thể để tăng khả năng khi gặp 1 case mới A thì mình có thể có tỷ lệ chọn được 1 method B có thể giải được nó.
- Một cách ảo giác thì có thể coi Stacking khá giống Boosting nhưng thay vì cố gắng xây 1 thằng học đi học lại từ các thằng khác thì mình sẽ để nhiều thằng học riêng với nhau và ghép lại sau.
- Được cái method này tốn tài nguyên.
Ensemble learning on Deep learning:

